Table of Contents
- 1 快速输入 #+BEGIN_SRC … #+END_SRC
- 2 代码按语法高亮
- 3 导出成HTML时的一些问题和技巧
- 3.1 生成目录表
- 3.2 为每个分节的标题添加标号
- 3.3 禁用下划线转义
- 4 让不同级别的标题采用不同大小的字体
- 5 org-mode与CUA的兼容性问题
- 6 两个与中文相关的问题
- 6.1 不关闭中文输入法,输入章节标题里面的星号
- 6.2 中英文字体混排时的表格对齐问题
1 快速输入 #+BEGIN_SRC … #+END_SRC
用org-mode写文章的的时候,经常需要引用代码片段或者程序输出,这就需要输入 #+BEGIN_SRC ... #+END_SRC 或者 #+BEGIN_EXAMPLE ... #+END_EXAMPLE 。输入的次数多了,就会想办法自动化,要么是用宏,要么是手工写 elisp函数,要么是借助 yasnippets 或者 skeleton 框架来写代码片段(比如 就发过一篇 《GNU Emacs Org-mode 写作的几个快捷方式》 ,那是借助 来实现的)。
但其实,org-mode已经内置了快速输入的方法: 输入 <s 再按TAB键 ,就会自动展开为 #+BEGIN_SRC ... #+END_SRC 。类似地,输入 <e 再按TAB键,就会自动展开为 #+BEGIN_EXAMPLE ... #+END_EXAMPLE 。
参考:
- GNU Emacs Org-mode 写作的几个快捷方式
2 代码按语法高亮
org-mode在导出成HTML时,可以对代码按照各自的语法进行高亮(只要在 #+begin_src 后面声明的语言是emacs所 支持的,其实也就是对应的major mode存在,比如声明为 #+begin_src js2 就要求 js2-mode 是存在的)。
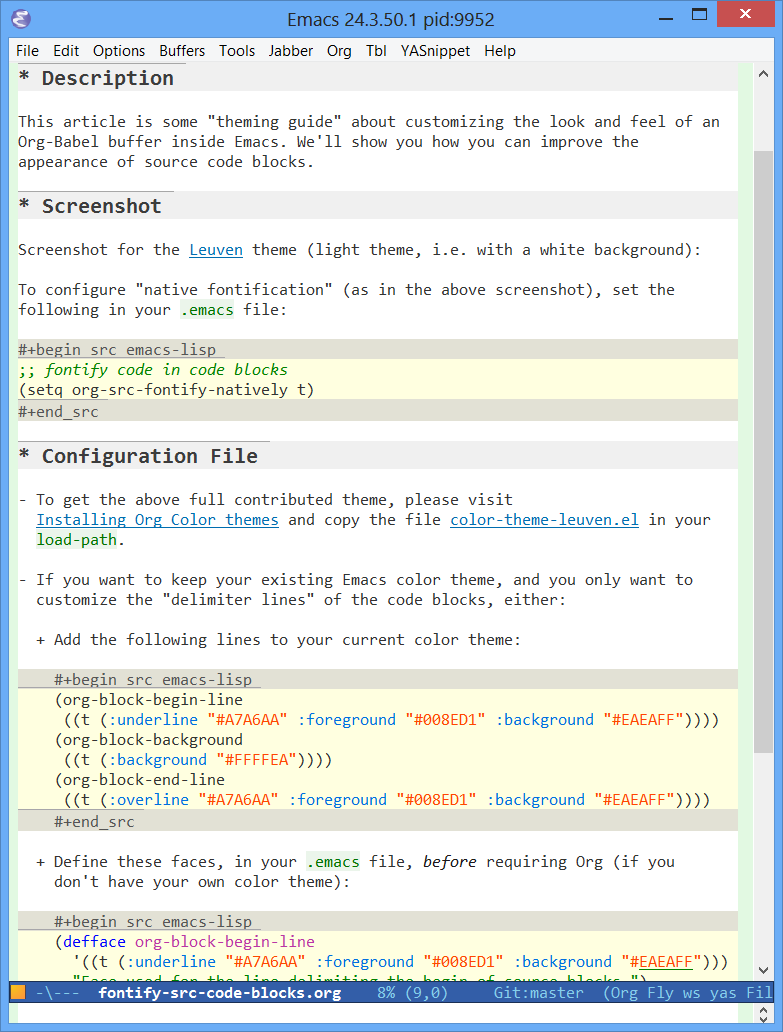
但能不能在编辑的时候,就可以在org-mode里面看到语法高亮的效果呢?答案是肯定的!
(setq org-src-fontify-natively t)
不过没有看到这个设置的更详细说明(我也没来看代码),在org-mode的文档中仅仅在这一节 看到一句: To turn on native code fontification in the Org buffer, configure the variable org-src-fontify-natively. 另外,这篇文档里有效果图:
3 导出成HTML时的一些问题和技巧
3.1 生成目录表
如果想在导出成HTML时在文档前面生成一个章节目录表(Table of Contents),那么可以在文件头部的 OPTIONS 里面添加 toc:t 参数
#+OPTIONS: toc:t ^:nil author:nil num:2
也可以设置 org-export-with-toc 这个变量
(setq org-export-with-toc t)
如果只想针对前面两个级别生成目录表,可以设置该值为相应的数字
#+OPTIONS: toc:2 ^:nil author:nil num:2
3.2 为每个分节的标题添加标号
导出成HTML时,如果不自定义css(这个高级话题留待下次再说),那么h1, h2, h3各个级别的标题只会字体大小有 点不同,不会呈现不同颜色,不会有缩进,于是阅读起来各节之间的关系就搞不清楚了。可以设置 org-export-with-section-numbers 让导出时为各章节的标题添加 1.2.3 这样的
比如:
* header foobar ** header hello ** header welcome * header hehe some text here ** header haha *** low level
导出时会变成:
1 header foobar1.1 header hello1.2 header welcome2 header hehesome text here2.1 header haha2.1.1 low level
如果只想针对前面两个级别生成分节号,可以设置该值为相应的数字。比如上面的例子如果设置 org-export-with-section-numbers 为 2 ,导出时就变成了:
1 header foobar1.1 header hello1.2 header welcome2 header hehesome text here2.1 header haha*low level*
3.3 禁用下划线转义
org-mode的文档在导出到html时,有一个挺烦人的问题就是 abc_def 会变成 abcdef,这其实是一种类似TeX的 写法,主要也就是在少数场景下有意义(其实与之相伴的还有一个 10^24 会变成 1024,不过这个对我影响不 大,因为我很少会用到这种写法)。
关闭这个功能的方法是在org文件头部的 OPTIONS 里面添加 ^:nil:
#+OPTIONS: ^:nil
参考:
上面的方法是针对当前文件的,如果想针对所有文件缺省关闭这个功能,需要在 ~/.emacs 中设置:
(setq-default org-use-sub-superscripts nil)
4 让不同级别的标题采用不同大小的字体
我从vim转到Emacs的其中一个原因是Emacs的GUI版本支持同时使用多种字体,比如上面的截图中就可以看到标题采 用了较大的字体。而以前对Emacs不太熟悉时,试用 期间无意中发现它能让 org-mode 的各种标题用不同大小的字体显示,还以为是比较神奇的功能,而不愿意切换到其他的theme去。
其实定制一下 org-level-1, org-level-2 等face的 height 属性就可以了(不过如果你用了其它theme的话, 要在加载这些theme之后再执行一遍下面这些配置,或者你把它们放在 org-mode-hook 中去执行):
(set-face-attribute 'org-level-1 nil :height 1.6 :bold t)(set-face-attribute 'org-level-2 nil :height 1.4 :bold t)(set-face-attribute 'org-level-3 nil :height 1.2 :bold t)))
5 org-mode与CUA的兼容性问题
虽然我不喜欢 cua-mode 里面的 C-c, C-x, C-v 等键,但 cua-mode 里面的 shift 选中,cua rectangle这些功能我还是比较喜欢的,所以我默认还是打开 cua-mode 。
不过 org-mode 跟 cua-mode 不兼容,主要的问题是无法按住 Shift 来选择文本了( <S-up> <S-home> <S-prior> S-M-b 等)。
安装 这个包即可解决这个问题。不过对于章节标题等特殊的地方,还是org-mode自己控制的。
6 两个与中文相关的问题
6.1 不关闭中文输入法,输入章节标题里面的星号
频繁打开/关闭输入法还是挺翻的,比如在连续输入章节或者列表项时,输入章节前面的 * 或者 列表项 前面的 * 或者 - 号,都要先关闭输入法,否则输入的是 × 和
不过可以用下面的方法解决:
(defun org-mode-my-init () ; ...... (define-key org-mode-map (kbd "×") (kbd "*")) (define-key org-mode-map (kbd "-") (kbd "-")) ) (add-hook 'org-mode-hook 'org-mode-my-init)
6.2 中英文字体混排时的表格对齐问题
org-mode的表格功能还是比较酷的,用起来相当方便(比较大的缺点是不支持跨列或者跨行合并单元格,甚至简单 一点,表格的某一行实际两行来存放内容(就是类似html编辑器里面那种单元格自动折行的显示方式)也不行)。
对于中文用户来说,最容易碰到的一个问题是一旦表格中同时有中英文的话,表格会无法对齐,中文比较少的时候 还好,只会有一点点错位,但当中文比较多时,这个表格就乱成一团,没法看了。

(本图非本人制作,摘自: )
这个问题困扰了很多人,大家也 折腾了各种方法。
首先是有人留意到,其实不仅仅是org-mode里面有问题,emacs本身在中英文混排时一个中文字符就跟两个英文字符 不是同样宽度的,除非有时碰巧了(比如当初我在Ubuntu下用Ubuntu Mono作为emacs默认字体时)。所以最开始我 一直在尝试各种字体,看哪种可以解决这个问题——但一直没有满意的方案,在一个机器上试验出来的结果在另外一 个系统上却不好使。最后发现是搞错了方向。
对于大部分的编辑器而言,我们只能选择一种字体(比如写代码常用的DejaVu Sans Mono, Inconsolata, Consolas),但这个字体中可能仅包含英文字符(或者也包含了其它拉丁字符),但大部分情况下不包含CJK字符, 对这种情况下对CJK字符的显示都是由系统来处理的,编辑器自己一般都不管。
不过Emacs毕竟是神的编辑器啊,它可以做到对不同体系的字符指定具体的字体,所以解决这个问题的办法是: 针 对中英文指定不同大小的字体,英文用小字,中文用大字 (别问我为什么,我是没去仔细研究。下面有一堆链接, 有兴趣的自己去看吧)。
(set-default-font "DejaVu Sans Mono 10")(set-fontset-font "fontset-default" 'unicode"WenQuanYi Bitmap Song 12") ;;for linux(set-fontset-font "fontset-default" 'unicode "宋体 12") ;; for windows
在你的环境上,你可能得对针对自己喜欢的编程字体去试验一下,看配哪个字号的中文字体(以及字号大小)可以 解决这个问题(或者可以试试下面的font.pl)。如果你还有日文、韩文什么的,可以详细地针对各种charset设定 字体(而不是像上面笼统地用 'unicode 来制定),详情请参看 。
参考:
- 这个脚本可以在所安装的字体中查找能对齐的中英文 字体及其字号,不过似乎只能在linux下跑,windows下不知道怎么搞